

Benjamin Ryzman
on 2 June 2026
What is InfiniBand?
When distributed workloads stall because nodes cannot exchange small messages quickly and consistently, the network is the limiting factor. How do you solve that problem? InfiniBand offers one solution.
InfiniBand is an interconnect, meaning the end-to-end communication system that links compute, storage, and accelerator nodes. It is implemented as a purpose-built network fabric, the switching and transport layer engineered to deliver high bandwidth and low, predictable latency between those nodes.
It is designed for low-latency communication, with tight latency distribution and high message rates, which make it particularly effective for running workloads such as distributed training, high performance computing (HPC) simulations, and large-scale data processing. In these environments, both median latency (typical response time) and tail latency (worst-case response-time, e.g., 99th percentile or P99) directly affect job completion time. Throughput – (how much work the system can process over time –) is often measured in messages per second, rather than bulk data transfer alone.
To understand what differentiates InfiniBand in practice, it helps to contrast its model with conventional TCP/IP networking. Rather than adapting Remote Direct Memory Access (RDMA) on top of an existing network stack, InfiniBand integrates it directly in its transport model, providing tight coordination between hosts and the fabric. For a deeper explanation of RDMA and how it removes the operating system and CPU from the data path to reduce latency and improve determinism, refer to the previous article.
In this blog, we’ll be deep diving into InfiniBand. We’ll discuss how it works from a technical point of view, explore the architectural and operational trade-offs that InfiniBand represents compared to conventional networking, and dive into where InfiniBand fits in modern infrastructure.
Understanding InfiniBand
The best way to explain InfiniBand is by starting from the application, not the network. InfiniBand’s architecture was designed around a simple goal: make distributed system components communicate as directly and efficiently as possible. To do so, InfiniBand exposes a messaging service that applications can access directly, instead of treating networking as a shared system resource mediated by the operating system.
This is a fundamental departure from TCP/IP-based designs. In a conventional stack, applications rely on the kernel to move data through sockets, buffers, and protocol layers. InfiniBand removes most of that path. Applications interact with the fabric through a messaging interface, and once a request is issued, data transfer proceeds without further involvement by the CPU or kernel.
With InfiniBand, applications send and receive complete messages delivered directly into application memory, rather than byte streams being reassembled incrementally from packets by the kernel. Under the cover, the hardware handles segmentation, transport, and reassembly. This simplifies communication from the application perspective: submit a message, and the InfiniBand fabric delivers it to the destination buffer.
Other architectural elements further streamline communication. Instead of applications requesting network services from the operating system, they establish direct communication channels between each other, which reduces latency and CPU overhead. Each channel consists of two endpoints, implemented as “queue pairs.” These queues are mapped into the application’s address space, allowing it to post operations directly to the network interface. The operating system still enforces protection and isolation of the virtual address space allocated to the applications, but this enforcement point is not in the communication data path.
How does InfiniBand’s messaging layer work?
InfiniBand is built around a messaging layer that defines how endpoints exchange data over the fabric. This layer exposes a set of transport services that implement the latency and throughput characteristics described above:
- Reliable and unreliable send/receive operations, which are broadly comparable to the distinction between TCP (reliable) and UDP (unreliable) in IP networks
- RDMA read and write operations, where a remote application exposes a memory region that can be accessed directly by a peer without involving the remote CPU
- Atomic operations for coordinated updates on shared data structures
- Multicast capabilities for distributing data to multiple endpoints efficiently
In practice, to drive this messaging layer, the programming model exposed by InfiniBand is built around a small set of well-defined operations that map directly to the hardware capabilities. Applications interact with the fabric by posting work requests – referred to in the InfiniBand architecture as a set of “verbs” – to queues. The terminology reflects the intent: a verb represents an action requested from the messaging service. Collectively, these verbs define the operations available to applications when using InfiniBand, such as requesting the transmission of a message to a remote endpoint.
The verbs are specified at the architectural level, and form the basis for higher-level APIs. InfiniBand’s specification itself does not mandate concrete APIs; these are provided by implementations. One example of an implementation is the OpenFabrics Alliance software stack. This stack exposes the verbs through open source libraries, such as libfabric, which integrate with InfiniBand hardware. Once submitted, work requests are processed asynchronously by the network interface, with completion events signaling when operations have finished.
Although InfiniBand exposes a simple messaging model to applications, it still implements a full network stack in the hardware underneath, which includes host channel adapters (HCA), which have a similar role as network interface cards (NIC), and InfiniBand switches. The transport layer provides reliability and ordering guarantees, while the link layer enforces lossless flow control.
This means the fabric prevents packet drops by ensuring that senders only transmit when receivers have available buffer space. This full scheduling of the fabric avoids retransmissions and keeps latency predictable, even under congestion.
Taken together, these design choices create a fabric where communication is treated as part of the system, rather than an external service. Applications exchange messages directly, data moves between memory regions without unnecessary copies, and the network enforces predictable behavior.
This is why InfiniBand is consistently used in environments where coordination cost dominates. The architecture reduces the overhead of communication to the point where scaling a distributed system becomes primarily a function of the application, not the network.
How InfiniBand supports modern distributed workloads
Tight coordination at scale
InfiniBand is a critical component in modern data center networking, because it delivers high throughput with consistently low latency. That combination makes it well suited to environments where many nodes must coordinate tightly and continuously.
HPC, scaling, and AI communication patterns
In HPC and large-scale AI infrastructures, jobs are split across thousands of processes that exchange data at fine granularity. InfiniBand supports this with scalable communication patterns that keep nodes synchronized as cluster size grows, while maintaining sufficient aggregate bandwidth to avoid bottlenecks as the cluster scales.
This scalability is a direct consequence of the fabric design. Efficient data aggregation and reduction mechanisms allow thousands of nodes to exchange and combine data continuously without introducing contention, which is critical for collective operations and tightly coupled workloads.
Lossless behavior and latency stability
The fabric is engineered to avoid packet loss through credit-based flow control and built-in congestion management. Data is not retransmitted under normal conditions, which keeps latency stable under load and avoids the cascading effects of retries that are common in TCP-based environments.
Reduced protocol overhead
InfiniBand also minimizes protocol overhead. Ethernet-based networks often rely on additional mechanisms to handle congestion, loops, and reliability. These layers introduce variability, which shows up as tail-latency spikes, retransmissions, and uneven throughput that slow collective operations, extend job completion time, and reduce overall cluster efficiency under load as the network scales. InfiniBand integrates these functions into the fabric itself, which keeps performance more predictable as cluster size increases.
RDMA-driven efficiency
RDMA is integral to this model. Data moves directly between memory regions across nodes, which removes extra copies and limits CPU involvement. The result is higher sustained bandwidth and tighter latency distribution for tightly coupled workloads.
Extended use cases: storage and accelerators
You see the same characteristics (low latency, high message rates, and direct memory access) in other patterns, such as NVMe over Fabrics for disaggregated storage, and GPU Direct RDMA for multi-node accelerator pipelines.
In GPU-heavy environments, tight integration between InfiniBand and accelerator platforms allows data to move efficiently between nodes without staging through host memory, which keeps both latency and CPU overhead under control.
Operational implications
For operators, this translates into a fabric that scales with workload size while reducing coordination overhead in the data path. InfiniBand introduces additional hardware and operational considerations compared to Ethernet, but in environments where latency and synchronization dominate system behavior, those trade-offs are made deliberately. In practice, this shifts effort toward upfront design and validation.
Challenges of InfiniBand
InfiniBand delivers its performance by being precise rather than forgiving. That precision shows up in day-1 design choices and day-2 operations. The main areas that require attention include topology design, Subnet Manager behavior, software stack alignment, mode selection, and ongoing validation and monitoring.
Topology
Topology – the arrangement of elements (links, nodes, switches, and so on) within the network – is the first place where issues surface. Most InfiniBand fabrics use a fat-tree topology to provide non-blocking bandwidth between nodes. A fabric can be fully connected and still behave as a blocking network. This typically happens when links are missing, uneven, or miswired. In practice, mis-cabled links and uneven port usage are among the most common causes of reduced bisection bandwidth (how much data a network can move across itself). This condition can be detected by checking per-port counters like portXmitWait (which indicates the amount of time a port has data to send but lacks flow-control credits) and portRcvErrors for signs of congestion and running all-to-all performance tests using the perftest suite of standard RDMA micro-benchmarks.
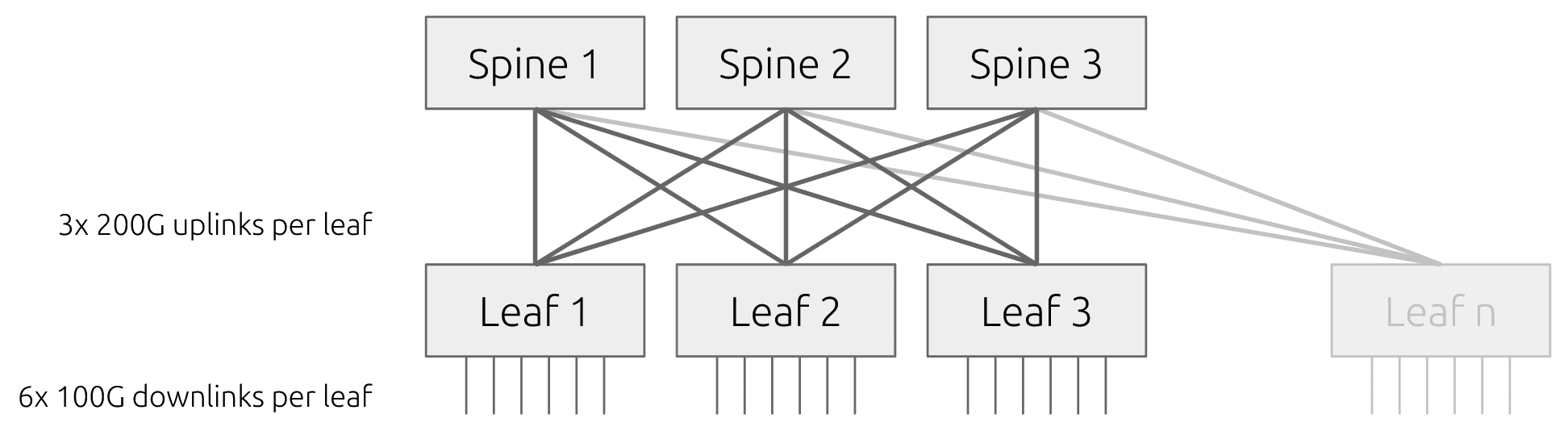
Fat-tree topology
A fat-tree is a hierarchical network design where bandwidth increases as you move up the layers of the network. Leaf switches connect to servers, while spine switches interconnect the leaves. The number of links between layers is sized so that the total available bandwidth remains consistent, allowing any node to communicate with any other node without contention. This symmetry is what enables non-blocking behavior at scale, as long as the topology is built and cabled correctly. The combined capacity of uplinks must match the combined capacity of downlinks, and cabling must follow a consistent pattern across leaf and spine layers.
Subnet Manager
The Subnet Manager (SM) controls how the fabric behaves. It is responsible for discovering the topology, assigning addresses, and programming forwarding tables across switches.
Only one SM is active at a time, with others on standby. Placement of the SM matters. Running the SM on a stable node such as a spine switch or a dedicated management host reduces the risk of disruptions. Priority and failover settings also need to be predictable. Poor SM configuration can lead to intermittent stalls that are difficult to distinguish from application issues.
Software stack alignment
The software stack needs to be aligned end to end, including compatibility between kernel drivers, user space RDMA libraries, HCA firmware, and the host kernel version. Common implementations include OFED (OpenFabrics Enterprise Distribution) and inbox RDMA stacks, which provide the kernel drivers and user space libraries required for InfiniBand. These components must remain compatible with the HCA firmware and host kernel version. Mismatches often do not cause hard failures. Instead, they show up as latency spikes or reduced throughput. In virtualized environments, features such as SR-IOV determine whether RDMA is available to workloads and how it behaves.
Mode selection
Mode selection also matters. InfiniBand supports both native RDMA through verbs and IP over InfiniBand (IPoIB). Native RDMA provides the lowest latency and highest throughput. IPoIB offers compatibility with IP-based tools but introduces additional overhead. It is common to find deployments where traffic unintentionally flows over IPoIB, which results in significant performance loss compared to native RDMA.
Validation and monitoring
Once the fabric is deployed, routing and flow become key factors in how it behaves under load. InfiniBand uses credit-based flow control to prevent packet loss. This keeps latency stable, but introduces sensitivity to configuration. Imbalanced routing, poorly generated forwarding tables, or partially blocking topologies can create hotspots. In larger fabrics, these effects can cascade and appear as intermittent slowdowns rather than clear failures.
Tools such as ibdiagnet and iblinkinfo help verify link health and topology correctness. Microbenchmarks can confirm expected latency and bandwidth between nodes. InfiniBand will continue to operate in a degraded state unless explicitly tested, which makes early validation important.
The physical layer also plays a role. InfiniBand links operate at very high speeds, so cable quality, optics, and installation practices matter. Faulty cables, excessive bend radius, or marginal optics can degrade performance across part of the fabric rather than failing outright.
In GPU-based systems, these constraints are amplified. Many designs map one InfiniBand port per GPU to maintain parallel communication paths. Collective operations depend on tight synchronization, so even small increases in latency can impact overall job completion time.
InfiniBand rewards careful design and disciplined operations. Teams used to Ethernet often need to adjust their approach. The fabric behaves more like a coordinated system than a best-effort network, and it benefits from the same level of validation and control as the workloads that run on top of it.
Conclusion
InfiniBand represents a different philosophy of data center networking. It prioritizes determinism, low latency, and tight coupling between systems. Those characteristics make it highly effective for specific classes of workloads.
For most CSPs and enterprises, InfiniBand will not replace Ethernet. It will coexist with it, serving as a specialized fabric where performance requirements justify the operational trade-offs.
Understanding InfiniBand sheds light on a broader trend. As workloads become more distributed and latency-sensitive, the network is no longer just a transport layer. It becomes part of the system design.
For operators evaluating or deploying InfiniBand, a few practical next steps emerge:
- Validate topology early and continuously, with explicit checks for symmetry and bisection bandwidth
- Standardize on a supported software stack (drivers, firmware, kernel), and keep it aligned across the fleet
- Use native RDMA paths where performance matters, and avoid unintended fallback to IPoIB
- Establish baseline benchmarks (latency and bandwidth) before onboarding production workloads
- Monitor fabric-level counters and SM behavior as part of regular operations
The next step in this series looks at RDMA over Converged Ethernet (RoCE), which attempts to bring some of these benefits into more familiar data center environments.


